Grammar without Grammaticality
by Geoffrey Sampson and Anna Babarczy
1 Introduction
1.1 Grammar before linguistics
Grammar (or “syntax”, as American linguists often prefer to call it) has lain at the heart of linguistic theorizing for decades now.[1] Rightly so: although grammar is often seen as a dry topic, it is grammar which provides the architecture of conscious, explicit thought and communication, so anyone who turns to linguistics in hope of gaining a clearer understanding of how human minds work must accept grammar as central to the discipline.
Pick up almost any issue of a mainstream modern linguistics journal, and you will find articles which analyse particular aspects of the grammar of particular languages by contrasting grammatical and ungrammatical word-sequences (with asterisks labelling the ungrammatical examples), by defining rules which aim to produce (“generate”) the grammatical examples while excluding the ungrammatical sequences, and by displaying tree structures that show how the rules group the words of particular grammatical sentences into multi-word units of various sizes nested within one another – phrases and clauses of various types.
But of course, grammar was studied before modern linguistics was inaugurated early in the twentieth century, by Ferdinand de Saussure’s lectures at the University of Geneva. If we look at how grammar was discussed before there was a subject called “linguistics”, we shall find much in common with present-day assumptions – but also, one important difference. We believe that on the rare occasions when that difference is noticed nowadays, its significance is severely misinterpreted.
As one representative treatment of grammar before Saussure, consider the grammatical section of John Meiklejohn’s book The English Language: its Grammar, History, and Literature, first published in 1886.
John Miller Dow Meiklejohn (1830–1902) was a remarkable man, whose career would be hard to parallel in the academic world of today. A Scot, Meiklejohn worked as a schoolteacher and a war correspondent, until in 1876 he became the first professor of education at St Andrews University. To supplement his salary he produced what one writer (Graves 2004: 15) calls “a veritable torrent” of textbooks on various school subjects, including history, geography, and English, which were widely distributed, and in some cases remained in use for many decades after his death. (He also produced what is still probably the most widely-read English translation of Immanuel Kant’s Critique of Pure Reason.) Our copy of The English Language is the 23rd edition (1902), which is one indication of its influence.[2] The book was intended primarily for trainee teachers; among other things it includes 41 pages of specimen question papers from the exams taken to gain teaching qualifications. It seems safe to infer that Meiklejohn’s approach to English grammar was uncontroversial and representative by the standards of his day.
In its style or flavour, Meiklejohn’s treatment of English grammar certainly feels different from modern linguistics writing. Notably, rather than aiming to make all his examples represent the colloquial English of his time, Meiklejohn tended to draw examples from literature, and often from quite high-flown genres far removed from everyday usage. But that is a superficial difference. In other respects, Meiklejohn covered much the same topics as one would find in a modern treatment of English grammar. He first examined the parts of speech and the inflection patterns of the language; then he went on to look at the various ways in which words can be grouped into simple and complex sentences. We often think of tree-structure diagrams as a speciality of modern linguistics, but Meiklejohn had them too, though they look superficially quite different from modern notation. Here is his structural diagram (p. 109) for a couplet from William Morris’s Jason,
And in his
hand he bare a mighty bow,
No man
could bend of those that battle now.
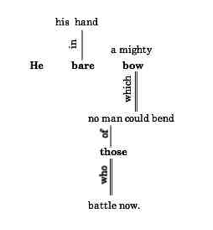
Meiklejohn glosses the single and double lines as representing respectively a preposition, and a “conjunction or conjunctive pronoun”; he does not explain his use of bold face, but bold v. plain seems to correspond to the head/modifier distinction. It seems to us that Meiklejohn’s diagram might be translated into a combination of modern dependency and phrase-structure notation as:
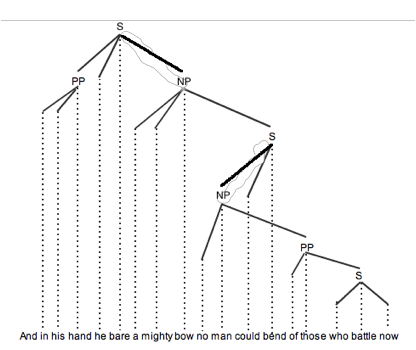
(where NP, PP, and S mean respectively “noun phrase”, “prepositional phrase”, and “clause”).
Where Meiklejohn’s approach differs fundamentally, rather than just cosmetically, from what would be normal today is that Meiklejohn’s examples are all positive. He only describes what does happen in English, he never contrasts this with hypothetical ungrammatical possibilities.
And so, naturally, Meiklejohn has no generative rules for producing the range of positive examples while excluding the ungrammatical. When he identifies a grammatical unit intermediate between the entire couplet and the individual words, say the phrase in his hand, he recognizes it as a unit not because in the process of using rewrite rules to derive the couplet from an initial symbol these three words are dominated by a single nonterminal symbol, but because the words fit together as a unit with a meaning.
Meiklejohn does, fairly often, identify some turn of phrase as to be avoided. Readers who think of late-nineteenth-century British society as imbued with snobbery and social anxiety might perhaps expect that those cases will be examples of socially-deprecated usage, such as double negatives. In fact Meiklejohn never mentions any examples of that sort. But there are two other categories of usage which Meiklejohn describes as not properly part of the language.
Often, Meiklejohn quotes obsolete usages from older authors and comments that they are not used in the modern language. An example would be Shakespeare’s use of as to introduce a relative clause in the context that kind of fruit/As maids call medlars (Romeo and Juliet Act 2, scene 1), where Meiklejohn (p. 75) comments “This usage cannot now be employed”. Occasionally he objects to a usage as illogical:
The Adverb ought to be as near as possible to the word it modifies. Thus we ought to say, “He gave me only three shillings,” and not “He only gave me three shillings,” … (p. 83)
Neither of these usage categories correspond to the way modern linguistics uses asterisks. Meiklejohn is not saying that these constructions will not be found in English; he is saying that they will be found, but are not to be imitated for different reasons – either because they are illogical or because they are too old-fashioned.
In more than one hundred pages of the book which deal with grammar, we have found just one case that seems directly comparable to the modern use of asterisks. On p. 23 Meiklejohn questions the idea that a “pronoun” is a “word that is used instead of a noun”, pointing out that this definition “hardly applies to the pronoun I. If we say I write, the I cannot have John Smith substituted for it. We cannot say John Smith write.” This does perhaps correspond neatly to a starred example *John Smith write in a modern linguistics publication. But even this case is included by Meiklejohn in order to query a part-of-speech definition – not in order to help draw a dividing line between word-sequences that are and are not grammatical in the language.
At least to a close approximation it is fair to say that Meiklejohn is not in the business of specifying word-sequences which cannot occur in English. He describes in considerable detail various syntactic structures which do occur in the language; he is not interested in contrasting these with other hypothetical word-sequences which do not occur.
When present-day academic linguists notice this absence in pre-modern accounts of grammar (we do not know of any recent linguist who has discussed Meiklejohn in particular), it seems to us that they standardly see it as exemplifying a pre-scientific approach to language description. Karl Popper has taught us that the hallmark of empirical science is falsifiability: a theory is empirical to the extent that it predicts a range of events which will not occur, so that it can be tested by seeing whether any potential falsifiers are in fact observed. Modern linguistics, or at least the central branch of linguistics concerned with grammar, is thought to have become a respectable science precisely by adopting a formal approach which allows a grammatical description to define a range of non-sentences alongside the range of well-formed sentences.
We on the other hand want to argue that Meiklejohn’s failure to do that makes his description more faithful to the fundamental nature of human language than a theory that defines a contrast between “grammatical” and “ungrammatical” word-sequences could be.
We have little doubt that, if it were possible to ask him, Meiklejohn would readily agree that his description of English was not a “scientific theory” comparable with the theories of the hard sciences. We doubt whether Meiklejohn would have taken that as a criticism of his work; but, whether he would have done so or not, we do not see it as such. If science requires potential falsifiers, then we do not believe that a good grammatical description of a human language can be truly “scientific”.[3]
Not all worthwhile discourse has the characteristics of scientific theorizing, after all (and Popper knew this as well as anyone). Think for instance of literary analysis. It is a normal enough activity to discuss the various genres of prose or poetic writing found in the literature of a language. In the case of some poetic genres (the sonnet, for instance) the definitions may be quite precise and formal. But it would be strange for an aspiring writer to describe a hypothetical genre of writing having some novel feature or features, and to ask “Would that be a valid kind of literature?” A question like that seems to misunderstand the kind of enterprise literature is. The only reasonable answer, surely, would be along the lines “Try it and see – write that way and discover whether you can attract a readership and, perhaps, imitators: if you can, then it’s a valid new literary genre”. There are no rules which allow or disallow a form of writing in advance as a candidate for literary consideration.
Grammar is rather like that. There are ways, in English or in another language, in which we know we certainly can put words together to produce successful structures of meaning, because utterances of those kinds occur specially often. But there is no particular range of ways in which it is not open to us to put words together – we can try anything, though if we speak idiosyncratically enough we may not succeed in getting through to our hearers. Human languages have grammar, but they do not have “grammaticality”.
1.2 All grammars leak
One reason to deny the reality of the “grammaticality” concept is the simple fact that no linguists have ever succeeded in plotting the boundary between the grammatical and the ungrammatical, for any language, despite many decades of trying. Edward Sapir ([1921] 1963: 38) famously stated that “All grammars leak”, and this remains as true now as when he wrote, almost a century ago. As David Graddol (2004) put it: “No one has ever successfully produced a comprehensive and accurate grammar of any language”. (Graddol argued that studying patterns of collocation in corpora offers a more realistic alternative.) Even if we date the enterprise of developing formal generative grammars not to Sapir but, more realistically, to Noam Chomsky’s Syntactic Structures, that book appeared more than half a century ago: time enough, surely, to have approached within sight of the goal for a few languages, if the goal were meaningful and attainable.[4] In reality, the most comprehensive grammars developed by linguists invariably turn out to have holes as soon as their predictions are checked against small samples of real-life usage. (That is true even when the samples represent edited written language; spontaneous speech, of course, is more anarchic still.)
One of the most serious attempts at a comprehensive generative grammar of English that has ever been published was Stockwell, Schachter, and Partee’s 854-page Major Syntactic Structures of English (1973). Those authors summarized their view of the ultimate feasibility of the exercise by quoting as a motto to their book a passage by the seventeenth-century grammarian James Howell (1662: 80):
But the English … having such varieties of incertitudes, changes, and Idioms, it cannot be in the compas of human brain to compile an exact regular Syntaxis thereof …
French culture is considerably more interested than that of Britain or the USA in the concept of linguistic correctness, which ought to make it a relatively favourable case for generative description – national newspapers commonly include columns responding to readers’ worries about whether this or that construction is good French; but at the end of an attempt lasting more than a decade by a team of French linguists to construct a generative grammar for that language, Maurice Gross (1979) concluded, in a thoughtful paper which received surprisingly little attention, that the enterprise was hopeless.
(Indeed, it is not just difficult to plot a boundary dividing the whole range of possible sequences of words of a language into grammatical and ungrammatical subsets: it can be surprisingly hard even to find cast-iron examples of individual ungrammatical sequences of English words. A word-sequence which at first sight looks clearly bad very often turns out to have a plausible use in some special circumstance. F.W. Householder 1973: 371 commented that it is necessary to “line up several articles and several prepositions in such examples, otherwise they become intelligible as some kind of special usage”.)
Commenting on Graddol’s paper quoted above, Anne Dalke (2010) compares his picture of grammar with “the sort of friendly adjustment that happens when we hang out w[ith] one another: there is a range of possible behaviors, but no rules.” Behaviour patterns but no binding rules: that is a good summary of how we see grammar.[5]
1.3 No common logic
It is not merely the fact that no-one has done it which causes us to doubt that grammaticality can be defined. More important, we see the grammaticality concept as founded on a false conception of the job which grammar does. Linguists often seem to imagine that the range of articulated ideas is somehow fixed and given to us prior to individual languages; the grammar of a particular language is seen as a device for clothing independently-existing structures of thought in pronounceable words. People have often seen logic as a realm, like mathematics, comprising structure that is eternal and independent of human culture, and have thought of individual languages as encoding that structure. The nineteenth-century Harvard professor Charles Carroll Everett wrote ([1869] 1891: 82) “the laws of grammar, which seem at first sight so hard and arbitrary, are simply the laws of the expresson of logical relations in concrete form.” Sometimes a language may provide alternative grammatical devices to express the same thought-structure, for instance a tidy room and a room that is tidy use different constructions to say the same thing; and often the historical evolution of a language will lead to it containing arbitrary grammatical irregularities. Both of these considerations mean that the grammar of a human language is likely to be much more complicated than the grammars of the artificial “languages” developed by mathematical logicians, such as the propositional calculus and the predicate calculus (which are designed to be thoroughly regular, and as simple as their functions permit). But, since the range of thought-structures is given in advance and therefore, presumably, finitely definable, it seems to follow that the range of grammatical structures in a language should be definable also, even if the definition has to be rather long.
The trouble with this is that it just is not true that English and other human languages express a common range of thought-structures which are independent of particular languages. Not merely the modes of expression, but the structures of thought expressed, vary from language to language.
In the first place, the thought-structures underlying a natural language cannot be equated with the expressions of a logical calculus. To see this, consider for instance that in both of the present authors’ native languages (and many others) there is an important contrast between and and but. (We are native speakers respectively of English and Hungarian, members of the Indo-European and Finno-Ugric families; the Hungarian words for “and” and “but” are és and de.) Yet in mathematical logic those different words translate into the same symbol, which some logicians write as & and others as ∧.
Some philosophers of logic have argued that natural-language distinctions which have no expression in their artificial symbolic calculi cannot be real intellectual distinctions. Gottlob Frege ([1918] 1967: 23) wrote:
The word “but” differs from “and” in that with it one intimates that what follows is in contrast with what would be expected from what preceded it. Such suggestions in speech make no difference to the thought.
For a logician it may perhaps be appropriate to use the word “thought” that way, but as linguists we are not interested in such a narrow definition. P and Q, and P but Q, clearly say different things in English – they are not interchangeable, as a tidy room and a room which is tidy perhaps are – so for us they express different “thoughts”. The same point could be made about many other English-language distinctions that have no parallel in formal logic.
The logician’s predicate calculus certainly is a system with a clear concept of grammaticality: certain sequences of its symbols are “well-formed formulae”, which can appear within proofs demonstrating that given conclusions follow from given premisses, while other, random, permutations of the same symbols are ill-formed and can play no part in proofs. Within a given logical system, the distinction between the two classes of symbol-sequence is entirely clearcut and predictable. But English and other natural languages cannot be mapped into the symbols of mathematical logic without (large) loss, so the fact that there are clear boundaries to well-formedness in a logical system does not imply that such boundaries exist in natural languages.
(Because formal logic is in this way a misleading guide to the nature of human language, we prefer to write about grammar encoding “thought-structures” rather than “logical structures”.)
1.4 “Chicken eat”
Furthermore, the conceptual distinctions which various natural languages express in their grammars can be very diverse. This is concealed from 21st-century Westerners by the fact that European civilization has historically been moulded by two languages, Latin and Ancient Greek, both of which had grammars that made certain conceptual distinctions extremely explicit, and which were so influential that modern European languages have all been moulded so as to make much the same distinctions almost equally explicit. (This involved large changes to some European languages as they existed in the mediaeval period; see e.g. Utz Maas (2009: sec. 3) on the case of German. Latin was actually the official language of Hungary as late as 1844.) Because of the dominant cultural role played by European-descended societies on the world stage from the nineteenth century onwards, many non-European languages have by now been similarly remoulded to express European thought-structures.
But there are or have been other languages. Within the total history of human speech, languages influenced in their grammar by Latin or Greek – although to us they may seem all-important – have certainly been only a tiny minority. Consider for instance the dialect of Malay/Indonesian spoken in the Indonesian province of Riau (east-central Sumatra), as described by David Gil. Gil (2001) writes:
Ask a speaker of Riau Indonesian to translate the English sentence “The chicken is eating”, and the answer might be as follows:
(14) Ayam makan
chicken eat
“The chicken is eating”
… ayam “chicken” is unmarked for number, allowing either singular or plural interpretations; and in addition it is unmarked for (in)definiteness, permitting either definite or indefinite readings. Similarly, makan “eat” is unmarked for tense and aspect, allowing a variety of interpretations, such as “is eating”, “ate”, “will eat”, and others.
So far, not too surprising, but this is only the tip of the iceberg. Arbitrarily keeping constant the singular definite interpretation of ayam and the present progressive interpretation of makan, the above construction can still be interpreted in many different ways, some of which are indicated below:
(15) Ayam makan
chicken eat
(a) “The chicken is being eaten”
(b) “The chicken is making somebody eat”
(c) “Somebody is eating for the chicken”
(d) “Somebody is eating where the chicken is”
(e) “The chicken that is eating”
(f) “Where the chicken is eating”
(g) “When the chicken is eating”
(h) “How the chicken is eating”
Gil points out that Riau Indonesian grammar allows ayam, “chicken”, to be understood as playing any conceivable thematic role vis-à-vis the act of eating – it could be the eater, the thing eaten, the cause of eating (15b), the beneficiary (15c), etc. etc.; and, looking at (15e)–(15h), we see
that the construction as a whole may be associated with an interpretation belonging to any ontological category: an activity, as in (14); a thing, as in (15e); a place, as in (15f); a time, as in (15g); a manner, as in (15h), and others.
Gil tells us that when he began learning Riau Indonesian, he assumed that any particular utterance of ayam makan must be intended in one of these interpretations and not others, but he came to see this assumption as a consequence of wearing European mental blinkers. Because European grammars require these interpretations to be distinguished, he at first took for granted that they must be exclusive alternatives for Riau speakers; later, he came to see the situation otherwise. There is a difference between ambiguity, and vagueness. For instance, in English the sentence The chicken is ready to eat is ambiguous between an interpretation in which the chicken will do the eating, and one in which the chicken will be eaten:
in any given utterance of the sentence, the speaker will have only one of these two interpretations in mind … Now consider the fact that, under the latter interpretation, the chicken could be fried, boiled, stewed, fricasseed, and so on. Although in many situations the speaker might know how the chicken is prepared, in many other situations he or she may not. But in those situations, the speaker simply would not care, and the sentence could still be appropriately uttered. Clearly, in such cases, we would not want to characterize chicken as ambiguous with respect to mode of preparation.
Rather, with respect to mode of cooking the English sentence is not ambiguous but just vague. In Riau Indonesian, Gil argues, ayam makan is vague (not ambiguous) between the various interpretations given in (14–15) above (and others). In a European language, one cannot be vague about most of those distinctions, because our grammars require us to express them, but in Riau Indonesian one can be and often is vague about them.
Standard Malay/Indonesian, which is one[6] of the many modern non-European languages that has been heavily influenced by European models, is significantly less vague and more “normal” (to Western eyes), having adopted grammatical apparatus allowing it to express various logical distinctions that speakers of European languages take for granted. But Riau Indonesian is indisputably a natural human language; it is less clear that Standard Malay can count as more than an artificial construct. According to McKinnon et al. (2011: 716), it has “almost no native speakers”.
We have quoted Gil at length because he expresses with unusual clarity the unfamiliar idea that the structures of thought expressed by the grammar of one language may be incommensurable with those expressed by another language’s grammar. (“Incommensurable” is perhaps not the ideal word here; we have not found a better one, and we hope that the example will show readers what we mean by it.) If that is so, then evidently different languages do not merely provide alternative methods of verbalizing a fixed range of thought-structures which are prior to any individual language. Languages define the structures of thought which they offer means of expressing, and different languages may define different thought-structures.
In that case, there is no obvious reason why we should expect a language to cease developing new thought-structures at a particular point in its history, any more than we would expect its literary tradition to cease evolving novel genres. Rather, we might expect the grammar of a language to remain open to innovation, and we might expect individual speakers to combine a great deal of imitation of other speakers’ grammar with at least a modicum of grammatical innovation. No doubt some individuals will be more innovative than others, in their linguistic usage as in other respects; and some communities will be more receptive to grammatical innovation while others are more conservative.
Perhaps there could be cases where some thoroughly hidebound community at a particular time gives up all grammatical innovation, and from then on limits itself slavishly to using only word-sequences that have clear grammatical precedents – and in a case like that it might make sense to draw a line between grammatical and ungrammatical word-sequences. But it seems to us that a case like that would be an exception requiring special explanation (and we wonder whether it could really happen). Certainly English in the 21st century is far from being such a language.
1.5 The case of Old Chinese
This way of looking at grammar and thought conflicts with assumptions that are deeply engrained in the modern discipline of linguistics. Many readers may feel that we are resting a great deal on one scholar’s understanding of the functions of two words in the dialect of an out-of-the-way corner of South-East Asia. Even in Indonesia, the dialect described by Gil has low prestige relative to Standard Indonesian (the grammar of which has been influenced by and is more commensurable with European grammars); and as we understand the situation, Riau Indonesian is used only in informal spoken communication. Some may feel that it is not all that surprising if a form of language limited to face-to-face chat among inhabitants of a remote backwater is strikingly vague – after all, the speakers will commonly know each other and be able to see what they are talking about, so background knowledge and the evidence of their senses might compensate for lack of verbal explicitness.
We therefore want to stress that although Gil happened to be discussing a low-prestige spoken dialect, a similar level of incommensurability with European grammar can be found in written languages of high civilizations.
Consider the following passage from the Confucian Analects. We quote the passage (chapter 23 of Book IX – a fairly typical example of Chinese of the classical period) in a romanization of the modern Mandarin pronunciation. (We do not show the Chinese script; for those who cannot read Chinese its impenetrability is offputting, while those who can read it can easily look the passage up in the original.) Classical Chinese, like Riau Indonesian, is an isolating language – its words do not vary to mark parts of speech, distinctions of tense or case, etc. – so for instance the word néng, glossed by us “be.able”, could equally be glossed “is.able”, “was.able”, “ability”, and so on – for each word we choose as neutral a gloss as English allows. Many words are polysemous, for instance the first word, zǐ, originally meant “son” but acquired the alternative senses “you” and “sir, master”; in such cases our gloss keeps things simple by giving only the sense relevant to the context in question.[7] Word-order rules are essentially like English, so in principle the glosses give readers all the information needed to understand the text – we have not left any clues to interpretation unstated. Readers might like to check how far they can make sense of the text, before looking at the translation below.
Zǐ yuē
master say
fǎ yǔ zhī yán
law talk ATTR speech
néng wú cóng hū
be.able not.have follow Q
gǎi zhī wéi guì
reform 3 do/be valuable
sùn yǔ zhī yán
mild concede ATTR speech
néng wú yuè hū
be.able not.have pleased Q
yì zhī wéi guì
unfold 3 do/be valuable
yuè ér bù yì
pleased and not unfold
cóng ér bù gǎi
follow and not reform
wú mò rú.zhī.hé yě yǐ yǐ
I there.isn’t what.about.3 ASSERT FINAL FINAL
Here is the translation offered by James Legge, the nineteenth-century interpreter of the Chinese classics to the English-speaking world:
The Master said, “Can men refuse to assent to the words of strict admonition? But it is reforming the conduct because of them which is valuable. Can men refuse to be pleased with words of gentle advice? But it is unfolding their aim which is valuable. If a man be pleased with these words, but does not unfold their aim, and assents to those, but does not reform his conduct, I can really do nothing with him.”
Comparing Legge’s English with the glosses, one can see correspondences, but these fall far short of any one-to-one matching of structural elements between the two languages. For instance, although the two opening words form a subject–verb structure, other words translated as verbs often have no subject – in the third line, who or what might “be able” to do something? (In this case Legge supplies the very general subject “men”, but it is not that Chinese omits subjects only where a European language might use a general term like French on, German man – subjects very commonly do not appear even when, if they did appear, they would probably be quite specific.) The last three lines are translated as an “if … (then) …” structure, but nothing in the Chinese marks them as such.
In the last line, rú zhī hé is an idiom, meaning something like “what about it/him?” (the three words could be glossed literally as “as 3 what”); the English “can do [anything] with him” is far more specific than the original. Following that are three words all of which have the force of making what precedes a definite and complete assertion. (The two words romanized yǐ are different words, beginning with different consonants in Old Chinese, which happen to fall together in modern Mandarin pronunciation.) This piling-up of assertive closing particles is typical of Classical Chinese prose, which often gives European readers the impression that it is very explicit about making an assertion but far from explicit about what is asserted.
With a language as structurally different from English as this, “translation” cannot be a simple replacement of elements of one language by corresponding elements of the other, as translation between modern European languages often is. What Legge has done (and all that a translator can do) would be better described as inventing wording that Confucius might have used, if Confucius had been an English-speaker.
We have discussed a Classical Chinese example at length in order to counter any suggestion that the kind of phenomena discussed by David Gil (what we might call “ayam makan phenomena”) are restricted to low-prestige local spoken vernaculars. The Analects is one of the “Four Books” which have provided the canonical philosophical underpinnings to one of the longest-lasting and most successful civilizations that has ever existed on Earth. It might not be a stretch to say that the Four Books fulfilled much the same functions for China as Plato’s dialogues and the New Testament fulfilled for Europe. The Classical Chinese in which they are written remained, with some development, the standard written language of China for millennia, until it was replaced early in the twentieth century by a written version of the modern spoken language (which is structurally rather different). Any suggestion that a language needs to offer structural equivalences to the grammar of modern European languages in order to serve the needs of a high civilization is just wrong.
To say that logic is universal and independent of individual cultures may be true, but it is not very relevant. Unlike the ancient Greeks, Chinese thinkers of the classical period had very little interest in logical matters. A persuasive discourse for them was not one whose successive statements approximate the form of syllogisms, but one in which they exhibit parallelism of wording (as in the Analects extract, e.g. fǎ yǔ zhī yán … sùn yǔ zhī yán; gǎi zhī wéi guì … yì zhī wéi guì). Everett’s claim that the laws of grammar reflect logical laws is grossly simplistic with respect to the European languages he was discussing; as a generalization about the languages of the world, it would be absurd.[8]
A sceptic might claim that the structural differences between Classical Chinese and modern European languages are smaller than they seem at first sight. We once read a paper in an academic journal[9] which argued that a human language could not be as lacking in explicit grammar as written Classical Chinese, so there must have been grammatical apparatus in the spoken language which was not recorded in writing. Chinese script is not phonetic but (simply put) assigns a distinct graph to each word; the suggestion was that when the language was a live spoken language, the words must have been inflected, but the script recorded only the roots, ignoring the inflexions.
If that were true, it would be remarkable that modern spoken Chinese preserves no remnants of the putative inflexion patterns;[10] and it would be mysterious how written Classical Chinese could have functioned as a successful communication system. And there are other reasons why it cannot be true. For instance, the language had contrasts between full and reduced forms of pronouns, as English you in unstressed positions can be pronounced ya, and the script distinguished these. Is it credible that a writing system would carefully distinguish pronunciation variants with no semantic significance, yet ignore aspects of pronunciation which were crucial for meaning?
Another possible sceptical line is to say that European languages as well as Chinese are often inexplicit about items that can unambiguously be recovered in context, and seeming vagueness in Chinese grammar results from taking this principle to an extreme.
The English verb “see” is transitive, but if someone draws our attention to something that has just happened in our presence, we can reply either “I saw it” or just “I saw”. The object of “see” is apparent from what was just said, so we will not spell it out; often, in English, we will nevertheless represent the object by an empty placeholding pronoun, but we do not have to do that. Languages differ in the extent to which they have the option of omitting the obvious; in Hungarian, the verb inflects differently for specific versus unspecific objects, so that látom means “I see it” while látok means “I see some unspecified object” or just “I have my sight”, and there is no possibility of neutralizing the contrast. Classical Chinese went the other way: much more often than English, it represented what was obvious by silence. Walter Bisang (2009) uses this strategy to challenge Gil’s account of ayam makan phenomena, with respect to Classical Chinese and various other languages of East and South-East Asia, though we are not sure whether Bisang would want to claim that the whole contrast in structural explicitness between Classical Chinese and European languages can be explained by reference to a Chinese preference for omitting the obvious.
We do not believe the contrast can be explained that way. Where Chinese is silent about something which European grammar would require to be explicit, frequently it is not obvious what is intended. Consider the fact that verbal elements often lack subjects. Those who translate Chinese poetry are familiar with the problem that it is often unclear whether the poet is describing his own activities, or reporting his observation of things done by others. A translation into a European language must opt for one or the other. If the view we have associated with Bisang applied to this, we would have to say that in the poet’s mind it was clear whether he was thinking “I did …” or “X did …”, but that, as written, the poems are ambiguous between well-defined alternatives. This is not the view taken by Chinese commentators themselves. James Liu uses a poem by the eighth-century-AD writer Wang Wei to discuss this issue. The poem begins:
Kōng shān bú jiàn rén
empty mountain not see people
dàn wén rén yǔ xiǎng
only hear people talk sound
and Liu (1962: 41) comments:
The poet simply says “not see people”, not “I do not see anyone” or even “One does not see anyone”; consequently no awkward questions such as “If no one is here, who is hearing the voices?” or “If you are here, how can the mountains be said to be empty?” will occur to the reader … the missing subject can be readily identified with anyone, whether the reader or some imaginary person. Consequently, Chinese poetry often has an impersonal and universal quality, compared with which much Western poetry appears egocentric and earth-bound.
The possible aesthetic advantages of this feature of Chinese grammar are not our concern here. Our point is that, for Liu, the subjectless clauses are not ambiguous, in the way that Gil describes “the chicken is ready to eat” as ambiguous – it is not that “see” and “hear” have subject slots which contain specific entries in the poet’s mind but which the reader is unable to identify, rather the subject role is genuinely blank for poet as well as readers, in the same way that an English statement about a cooked chicken being ready may be vague about cooking method.
1.6 It cuts both ways
If a sceptic, who believes that the range of possible thought-structures is prior to particular languages, continues to press the point that prose like the Analects extract must have been understood as meaning something more fully articulated than it appears at the surface, comparable to the Legge translation, because only a structure of thought with that degree of articulation “makes sense”, then another response is to confront the sceptic with cases where an exotic grammar is more specific than English. It is not that languages independent of the European classical heritage always differ from European languages in the direction of structural vagueness. Sometimes it is the other way round. Franz Boas gave many examples where the grammars of various American Indian languages require speakers to be explicit about issues which European languages commonly leave open. He takes as an example the English sentence “The man is sick”:
We express by this sentence, in English, the idea, a definite single man at present sick. In Kwakiutl [a native language of British Columbia, nowadays called Kwak’wala] this sentence would have to be rendered by an expression which would mean, in the vaguest possible form that could be given to it, definite man near him invisible sick near him invisible. … In Ponca, one of the Siouan dialects, the same idea would require a decision of the question whether the man is at rest or moving, and we might have a form like the moving single man sick. (Boas 1911: 39)
If we say that someone is ill (or, in American English, sick), are we happy to agree that we have spoken ambiguously, because the hearer might understand us to be referring either to someone we can see or someone out of sight (or, to someone moving or someone at rest)? The present authors do not have any feeling that, in English, the utterance is “ambiguous” in these ways – commonly, if we say that someone is ill, there will be no thought in our mind about whether he is visible or not; we may not even know whether he is moving. “X is ill” represents a thought complete in itself.
If the sceptic agrees with that, and sees Kwakiutl and Ponca as requiring specificity about issues which the pre-existing range of possible thought-structures allows to be left vague, while at the same time insisting that the Analects passage must have been interpreted by its original Chinese readers with a degree of explicitness that resembled the Legge translation more than the surface Chinese wording, because that wording is “too vague to make sense”, then it is fairly clear that “making sense” is being understood as “translatable without much loss or addition into the language I speak”. Surely we cannot take very seriously the idea that just those languages which we happen to speak are languages whose grammars are neither unnecessarily specific nor unduly vague but, like Goldilocks’s porridge, just right?
We take it, rather, that the grammars of different languages are fairly good guides to the structures of thought available to their respective speakers. “I there.isn’t what.about.3” would not be a complete thought for us as speakers of modern English or Hungarian, but for a Chinese of 2500 years ago it was. “The man is ill” would not be a complete thought for a Kwakiutl or Ponca speaker, but, for us, “The man is ill” in English, or A férfi beteg in Hungarian, is a complete thought.
Consequently, we shall take for granted from now on that the grammar of a language is a system which has to be evolved by the community of speakers, along lines which are not set in advance and do not lead towards any natural terminus; so that different languages may have developed structurally in different directions, and it is open to individual speakers of a language to play their part in the continuing process of grammatical development.
(Even the most central, “core” constructions must have begun as novel cultural developments once. Guy Deutscher (2000) has shown that in the case of the very early written language Akkadian we can actually witness the process by which it equipped itself for the first time with complement clauses, by adapting a grammatical element previously used for a different purpose; see p. 000 below.)
1.7 Vocabulary differences
Incidentally, this picture of how languages behave in the domain of grammar, which many linguists find intuitively difficult to countenance, would seem very normal in the domain of vocabulary. Most people recognize that individual languages will often develop vocabulary items that cannot straightforwardly be translated into the vocabulary of other languages, and that innovation in vocabulary is a bottom-up process in which any individual speaker can participate, though no doubt some individuals do much more of it than others. (When we think about incommensurability of vocabulary, probably most of us think first of words for sophisticated cultural abstractions, but plenty of examples can be found at the level of simple concrete everyday words. Ernst Leisi, whose book Der Wortinhalt is enlightening on vocabulary incommensurability between German and English, discusses for instance the difficulty of finding good English translations for the concrete nouns Zapfen and Scheibe, neither of which relate to culture-specific phenomena (Leisi 1974: 30).)
Furthermore, those of us who are parents are surely familiar with the idea that grammar acquisition tends to lag behind acquisition of vocabulary – a small child will typically have mastered many words for concrete objects, animals, food, and so on, at a stage when his or her grammatical production seems very impoverished relative to what it will be in later years. If people accept that learning lexical items is genuinely a matter of acquiring concepts as well as verbal forms which are not given in advance, it might seem odd that they are so attached to the idea that acquiring grammar is about merely learning how to verbalize pre-existing structures of thought. Would we not expect progress to be faster where more is predetermined?
The explanation, we suggest, is that once one has mastered the grammar of one’s mother tongue, the fact that its structures provide the architecture of one’s articulate thinking makes it near-impossible to conceive that those structures could be otherwise – they become the structures which “make sense” to us. We can fairly easily imagine what it would be like not to have the concept “elephant”, but we cannot imagine what it would be like not to have a past tense. That is why grammar feels as if it were predetermined; but if we look at grammatical differences between languages, we see that it cannot be.
(It is true that there have been linguists who believe that even vocabulary is in some sense predetermined. Notably, Jerry Fodor’s book The Language of Thought (1975) argued that any first language is acquired by learning how to translate its forms into those of a common, innately given “language of thought”; and Fodor focuses mainly on the vocabulary side of languages. Fodor believes that although the vocabularies of languages cannot always be put into a one-to-one correspondence with each other, they are commensurable in the sense that any vocabulary item in any language has a perfect translation into the “language of thought”, which itself has a finite vocabulary – some of the translations might equate individual words with multi-word structures, but one will be able to get from any language via the language of thought to perfect equivalents in any other language. However, Fodor’s argument is wholly aprioristic. He never compares elements of English with those of any other language, and he says very little about what he envisages the hypothetical “language of thought” to be like.[11] We do not believe that questions about relationships between the world’s languages can usefully be addressed without looking at any languages.)
1.8 What can be said about grammar
Of course, while ours may be a minority position, we are by no means the first linguists in the past half-century to have questioned the concept of “grammaticality”. We have discussed that issue in this introductory chapter in order to provide a background for the detailed studies in later chapters; the main point of the book is not merely to argue against the grammaticality concept, but to present a range of concrete positive findings about grammar that emerge when one gives that concept up. The fact that grammaticality may be a myth does not imply that there is little to say about grammar in general, above the level of studies of particular constructions in individual languages. It might well be desirable for the division of effort in linguistics to be rebalanced towards a larger share for research on individual languages, dialects, language-families, etc., and a smaller share for general linguistics, but a smaller share should certainly not be a zero share. There is plenty to say about grammar in general. This book aims to say some of it.
Our way of thinking about “grammar in general”, though, does not involve advocating some novel way of defining grammars of human languages, as some readers may be expecting. For decades, theorists of grammar have been arguing the toss between formalisms such as “X-bar theory”, “lexical-functional grammar”, “tree-adjoining grammar”, “relational grammar”, and many others. We shall not be adding a new candidate to this list of rival ways of defining grammars, nor shall we be taking sides in the debates between existing candidates – we do not see much point in those debates.
We recognize that there are some structural generalizations to be made about grammar in any human language. People have been aware for a very long time that hierarchy – tree structure – is central to grammar. Words group into small units such as phrases, the small units group into larger units, and so on up to the largest units having structural coherence, complex sentences containing subordinate clauses which may in turn themselves contain clauses at lower levels of subordination. When grammatical constructions involve shifting groups of words from one position to another (say, as questions in English involve shifting the questioned element from its logical position to the front – “Which brush did you paint it with? I painted it with that brush”), the words moved will typically be a complete unit in the tree structure, rather than (say) comprising the last word or two of one unit and the opening word(s) of the following unit.
We do not need the linguistics of the last century to tell us about the centrality of tree structure in grammar, though it was perhaps only in the twentieth century that anyone thought to ask why this particular abstract type of structure should be so important. That question was answered in 1962 by the psychologist, artificial intelligence expert, and economics Nobel prizewinner Herbert Simon. Simon’s essay “The architecture of complexity” (Simon 1962) showed that any complex products of gradual (cultural or biological) evolution are, as a matter of statistical inevitability, overwhelmingly likely to display hierarchical structure.[12] It is just much easier to develop small units and then build on them stepwise in developing larger structures, than to move from no structure to complicated structure in one fell swoop. The fact that we each learn our mother tongue by building up from small to large in this way is why we, like Meiklejohn, can recognize sub-sentential word sequences such as in his hand as meaningful units.
Human languages are culturally-evolved institutions, so Simon’s argument explains why tree structure is commonly found in them – though we shall see in Chapter 6 that even this rather weak generalization about human-language grammar is not without exceptions. The idea that grammatical theory should be about detailed descriptive formalisms stems from a widespread belief that the languages of the world share universal structural properties which are much more specific than a mere tendency to assemble large units out of smaller ones. As Steven Pinker (1995: 409) has put it:
the babel of languages no longer appear to vary in arbitrary ways and without limit. One now sees a common design to the machinery underlying the world’s language, a Universal Grammar.
(The formalisms serve as a way of codifying the alleged universal grammar: the idea is that the correct formalisms will provide a definition for any structure which obeys the universal constraints on language diversity, but a hypothetical “unnatural” language which violates the constraints would not be definable within the formalisms.)
We, on the other hand, see no mechanism that could constrain ever-changing languages scattered across the face of the planet all to share detailed structural features – and so far as we can tell, contrary to Pinker’s claim they do not in fact do so.[13] Consequently we are not interested in descriptive formalisms. We believe that linguists should be encouraged to describe the diverse language structures of the world using whatever descriptive techniques they find clear and convenient.
The sort of questions which seem to us worth asking about grammar in general are questions like these:
· If the grammatical structure of a language is developed by the community which uses it, and acquired by individual speakers, along lines that are not prescribed in advance, how refined does that structure become?
· Are there particular areas of grammar which are less, or more, precisely defined than other areas?
· Do the answers to some of these questions differ as between written and spoken modes of language?
· Can we make any generalizations about the path taken by children towards the levels of grammatical refinement achieved by adults? (Many linguists have studied the early stages of child language acquisition, as children take their first steps away from one-word utterances and begin to put words together – later stages have been less studied, perhaps because to linguists who believe that the endpoint of the process is in some sense given in advance, those stages seem less interesting.)
As phrased here, these questions are general, in the sense that they do not relate to particular constructions in individual languages, which might not have counterparts in other languages. They arise for all languages (except that the question about written and spoken modes applies only to languages which possess both modes).
However, the questions can only fruitfully be studied by reference to a particular language or languages. It is reasonable to hope that the findings for one language will be at least suggestive for other languages, but how similar languages are with respect to these issues could emerge only from comparison of separate studies. Since the questions are rather new, we have had the opportunity of researching aspects of them for only one language: modern English, the language which both co-authors share.
Thus, to summarize, we have set out to enquire into the growth and limits of grammatical precision in English.
1.9 The computational viewpoint
The direction from which we have approached the topic is computational linguistics. Both co-authors have spent years developing so-called treebanks – structurally-annotated electronic samples of real-life English of various written and spoken genres – intended largely as sources of data for computational natural-language analysis and processing systems. For some readers, this may seem a specialist discipline remote from their own interests. However, the work has features which give its results particular relevance for the pure academic study of language as an aspect of human cognition and behaviour.
When we set out to equip samples of real-life language with annotations identifying their grammatical structures, we have to deal with everything the samples contain; we cannot pick and choose. We have to use a scheme of annotation which provides means of logging any structural phenomena that crop up, and we must develop explicit guidelines specifying how the annotation applies to debatable cases – in order to ensure that the statistics extracted by our computers reliably count apples with apples and oranges with oranges. The point has been well put by the computational linguist Jane Edwards (1992: 139):
The single most important property of any data base for purposes of computer-aided research is that similar instances be encoded in predictably similar ways.
These imperatives of comprehensiveness and consistency give us (we believe) a clearer perspective on the degrees of structural complexity actually present in various areas of the language than is commonly achieved by non-computational approaches. A linguist whose goal is to develop rules reflecting speakers’ linguistic competence, as an aspect of their psychological functioning, will quote examples that clearly bear on known issues about grammar rules, but may overlook or avoid discussing examples containing messy little turns of phrase whose implications for the overall grammar are not clear one way or the other.
In principle that might be a reasonable thing to do. A scientist will often be justified in looking for an equation which accounts well for the bulk of his data-points, discarding a few anomalous readings where the data may somehow have been corrupted. The trouble is, with language it is not a question of a handful of anomalies: in our experience, a very high proportion of real-life usage contains oddities which one might be tempted to set aside – only, as computational linguists, we cannot set them aside. The picture of grammar which emerges from non-computational approaches tends to be neater and simpler than the reality, to an extent that (we believe) seriously distorts our understanding of what kind of phenomena languages are.[14] Languages are often seen as artificially schematic, Esperanto-like systems, whereas in reality they are grainy, irregular accumulations of complication and inconsequentiality.
(Ironically, there is one class of languages which really are of the former, schematic kind: computer programming languages. But our computational research teaches us that human languages are not at all like programming languages.)
The proof of the pudding is in the eating. Some of the findings we discuss in later chapters should be of interest, we believe, to anyone who cares about the subtle human ability to speak and understand language. We would not have been led to these findings if we had not been working within a computationally-oriented intellectual framework. But, irrespective of how we came to them, the findings speak for themselves. They have things to say to linguists working in almost any framework.